K2E-B-G6-1 · Paper Note
NeRF — Neural Radiance Fields
- Description:NeRF 论文笔记 — 5D MLP 表示连续辐射场,可微体渲染积分、位置编码、分层采样、定量结果与代码走读。NeRF-SLAM 系列的表示基石
- My Notion Note ID:K2E-B-G6-1
- Created:2024-03-31
- Updated:2026-06-11
- License:转载欢迎:转载请注明作者 Yu Zhang 并附原文出处(yuzhang.io)
Table of Contents
- 1. Summary
- 2. Key Contributions
- 3. Method
- 4. Experiments & Results
- 5. Ablation & Discussion
- 6. Strengths / Limitations / Future Work
- 7. Code Walkthrough
- References
1. Summary
Title: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis Authors: Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng (UC Berkeley, Google Research, UC San Diego) Paper: arXiv:2003.08934 (ECCV 2020 Oral) Github: bmild/nerf
NeRF 用一个 MLP 参数化连续的 5D 辐射场:输入 3D 位置 + 2D 视角方向,输出体密度 + 视角相关颜色,配合可微体渲染做新视角合成。整个场景仅需 ~5 MB 网络权重,对比 LLFF(Local Light Field Fusion,基于多平面图像的 2D 特征新视角合成,Mildenhall et al. 2019)压缩约 3000×,且可连续可微采样任意视角。
在 Realistic Synthetic 360° 数据集上 NeRF PSNR 31.01 dB,显著超越 SRN(Scene Representation Networks,连续隐式函数场景表示,Sitzmann 2019,22.26 dB)、NV(Neural Volumes,神经体素视角合成,Lombardi 2019,26.05 dB)、LLFF (24.88 dB)。后续 NeRF-SLAM 系列(iMAP / NICE-SLAM / NeRF-LOAM...)均以此为表示基础,它也被 3DGS 在渲染速度上超越但在表示精度上仍有影响力。
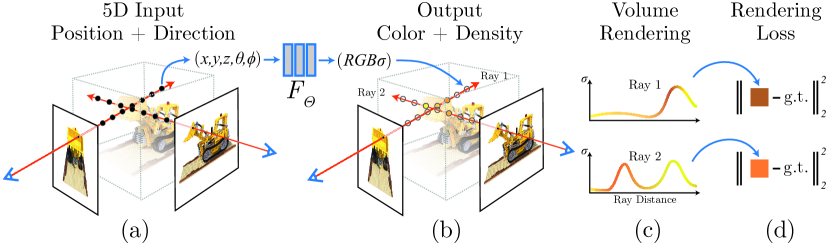
2. Key Contributions
- 5D 神经辐射场:统一表达几何(密度 )与视角相关外观(颜色 ),密度与方向无关,颜色与方向有关(模拟高光)
- 可微体渲染 + 分层采样:连续体积渲染 alpha 合成公式 + 粗/细两网络的重要性采样,大幅减少空/遮挡区域计算浪费
- 位置编码:将坐标映射到高维三角函数空间,使 MLP 捕获高频细节(后被 Instant-NGP 哈希编码替代,见 Instant-NGP 笔记)
3. Method
3.1 5D 神经辐射场
MLP :
- 输入:3D 位置 + 视角方向 (3D 笛卡尔单位向量,概念上 2D 球面角)
- 输出:颜色 + 体密度
关键约束: 只依赖位置(多视角几何一致); 依赖位置 + 方向(模拟高光等视角相关效果)。
3.2 网络结构
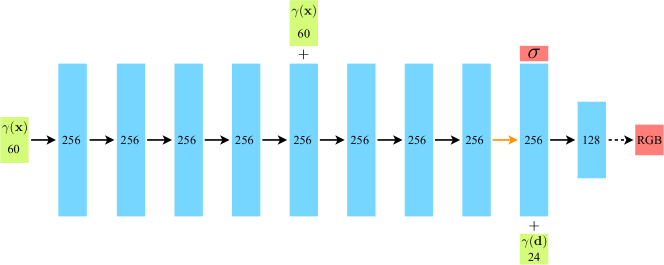
- (60 维)→ 8 层全连接(256 通道,ReLU),第 5 层拼接 (skip connection)→ 输出 (ReLU 保非负)+ 256 维特征向量
- 特征向量拼接 (24 维)→ 1 层(128 通道,ReLU)→ sigmoid → RGB
3.3 体渲染
沿光线 积分颜色:
透射率(光走到 未被遮挡的概率):
离散化(分层求积 + alpha 合成,):
令 → 即标准 alpha 合成(与 3DGS 混合公式同源,见 3D Gaussian Splatting)。
3.4 位置编码
MLP 直接处理低维坐标偏向低频(图像细节模糊)。每个标量 映射到 维:
位置:(输入 60 维);方向:(输入 24 维)。坐标归一化到 。
3.5 分层采样
粗网络: 个分层采样点 → 得权重 ,:
细网络:以 为概率分布重要性采样 点,用 点渲染。集中算力在有物体的区域。
3.6 损失与训练
粗 + 细网络共同监督:
Adam(,lr 指数衰减),batch 4096 光线,单 V100 约 100–300k 迭代(1–2 天/场景)。
4. Experiments & Results
数据集:
- Diffuse Synthetic 360°(4 个漫反射合成物体,512×512)
- Realistic Synthetic 360°(8 个光追合成物体,800×800)
- Real Forward-Facing(8 个真实场景,~1008×756,手持拍摄)
主要定量结果(Table 1):
| 数据集 | 方法 | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|
| Realistic Synthetic 360° | SRN | 22.26 | 0.846 | 0.170 |
| NV | 26.05 | 0.893 | 0.160 | |
| LLFF | 24.88 | 0.911 | 0.114 | |
| NeRF | 31.01 | 0.947 | 0.081 | |
| Real Forward-Facing | SRN | 22.84 | 0.668 | 0.378 |
| LLFF | 24.13 | 0.798 | 0.212 | |
| NeRF | 26.50 | 0.811 | 0.250 |
Realistic Synthetic 单场景最优:Lego 32.54 dB,Hotdog 36.18 dB,Drums 25.01 dB(最难,高频纹理多)。
5. Ablation & Discussion
消融实验(Realistic Synthetic 360°, Table 2):
| 去掉的组件 | PSNR | ΔPSNR |
|---|---|---|
| 完整模型 | 31.01 | — |
| 无位置编码 (PE) | 28.77 | −2.24 |
| 无视角相关性 | 27.66 | −3.35 |
| 无分层采样 | 30.06 | −0.95 |
| 25 张图(vs 100) | 27.78 | −3.23 |
| 无 PE + 无视角 + 无分层 | 26.67 | −4.34 |
视角相关性影响最大( dB)→ 非漫反射场景高光建模至关重要;位置编码其次( dB);分层采样对精度提升适中(主要贡献是计算效率)。位置编码频率数 的影响较小:(30.59)和 (30.81)均与 (31.01)相近;图像数量从 100 减到 50(29.79)再到 25(27.78)影响较大。
6. Strengths / Limitations / Future Work
优点:
- 连续可微的场景表示,可任意分辨率查询
- ~5 MB 表示一整个场景(3000× vs LLFF)
- 新视角合成质量当时 SOTA,对细节(高光、半透明)刻画显著优于先前方法
局限:
- 极慢:单 V100 每场景训练 1–2 天,推理每帧秒级
- 每场景独立训练,无跨场景泛化
- 需要精确已知相机位姿(后续 NeRF-- / iNeRF 解决部分)
- 仅支持静态场景,动态物体 / 移动人物需要特殊处理
衍生:
- 速度:Instant-NGP(多分辨率哈希,分钟级训练)→ Instant-NGP
- 场景表示替代:3DGS(高斯溅射,实时渲染)→ 3DGS
- SLAM 集成:iMAP / NICE-SLAM / NeRF-SLAM / NeRF-LOAM → K2E-B-G5 系列
- 可变形:Nerfies(可变形 NeRF)→ Nerfies
7. Code Walkthrough
代码库:bmild/nerf(TensorFlow,原版官方实现)
7.1 目录结构
nerf/
run_nerf.py ← 主训练脚本(入口)
run_nerf_helpers.py ← 核心渲染函数(体渲染、采样、网络定义)
load_blender.py ← 合成数据集(Blender)读取
load_llff.py ← 真实前向数据集读取
load_deepvoxels.py ← DeepVoxels 数据集读取
tiny_nerf.ipynb ← 简化教学版实现(推荐入门阅读)
render_demo.ipynb ← 预训练模型渲染
extract_mesh.ipynb ← marching cubes 提取网格
paper_configs/ ← 复现论文结果的配置文件
7.2 主训练流程(run_nerf.py)
main()
├── load_data() ← 读图像 + 位姿 (N × 4×4 矩阵)
├── create_nerf() ← 初始化粗/细两个 MLP + 位置编码函数
└── 训练循环:
sample_rays() ← 从随机像素采光线 (o, d)
render() ← 调 run_nerf_helpers.render_rays()
loss = MSE(pred, gt) ← 粗 + 细网络各自 loss (式 6)
optimizer.step()
每 N 步: test_render() + save_weights()
7.3 核心渲染(run_nerf_helpers.py)
关键函数调用链:
render_rays(rays_o, rays_d)
├── sample_along_ray() ← 分层均匀采样 N_c 点 (式 5 粗采样)
├── query_network(pts_c) ← 粗网络查询 (σ, c)
├── volume_render() ← alpha 合成 (式 3)
├── importance_sample() ← 以粗权重为 PDF 重要性采样 N_f 点
├── query_network(pts_f) ← 细网络查询
└── volume_render() ← 细网络 alpha 合成 → 最终颜色
volume_render() 直接实现式 (3):计算 (累积透射率前缀积)→ → 加权求和颜色。
7.4 位置编码实现
# run_nerf_helpers.py
def positional_encoding(x, L):
# x: [..., D], L: 频率数
freqs = 2.**tf.range(L) # [L]
# sin / cos 各 L 个频率
return tf.concat([tf.sin(freqs*x[...,None]),
tf.cos(freqs*x[...,None])], axis=-1)
# 输出: [..., D * 2L]
位置用 ,方向用 ;坐标须先归一化到 。
7.5 关键参数(config_lego.txt)
| 参数 | 值 | 含义 |
|---|---|---|
N_coarse |
64 | 粗网络采样点数 |
N_fine |
128 | 细网络重要性采样点数 |
L_pos |
10 | 位置编码频率数 |
L_dir |
4 | 方向编码频率数 |
netdepth |
8 | MLP 层数 |
netwidth |
256 | MLP 通道数 |
lrate |
5e-4 | 初始学习率 |
N_iters |
200000 | 训练迭代数 |
N_rand |
4096 | 每步 batch 光线数 |
7.6 paper-vs-code 差异
| 论文 | 代码 |
|---|---|
| 粗 + 细两网络结构 | 代码用同一 create_nerf 分别初始化 model 和 model_fine,权重独立 |
| 方向为 2D 球面角 | 代码用 3D 笛卡尔单位向量(方向 embed 前先归一化),等价但实现更简洁 |
| 论文图示 skip connection 在第 5 层 | 代码 skips=[4](0-indexed),即第 5 层输入拼接原始编码 |
| 训练 100–300k 步 | 配置文件默认 200k;复现各场景需用 paper_configs/ 下对应 config |
References
| 类别 | 链接 |
|---|---|
| 论文 | Mildenhall B. et al. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV Oral. arXiv:2003.08934 |
| 代码 | github.com/bmild/nerf |
| 项目页 | matthewtancik.com/nerf |
| 速度续作 | Instant-NGP → 本系列 |
| 场景替代 | 3DGS → 本系列 |
| SLAM 应用 | iMAP / NICE-SLAM / NeRF-LOAM → K2E-B-G5 NeRF-SLAM 系列 |