K2E-B-G5-2 · Paper Note
NICE-SLAM
- Description:NICE-SLAM 论文笔记 — 分层特征网格 + 预训练 MLP 解码器的神经隐式 SLAM,解决 iMAP 的大场景遗忘和过平滑问题
- My Notion Note ID:K2E-B-G5-2
- Created:2024-03-31
- Updated:2026-06-08
- License:转载欢迎:转载请注明作者 Yu Zhang 并附原文出处(yuzhang.io)
Table of Contents
- 1. Summary
- 2. Key Contributions
- 3. Method
- 4. Experiments & Results
- 5. Ablation & Discussion
- 6. Strengths / Limitations / Future Work
- 7. Code Walkthrough
- References
1. Summary
Title: NICE-SLAM: Neural Implicit Scalable Encoding for SLAM Authors: Z. Zhu, S. Peng, V. Larsson, W. Xu, H. Bao, Z. Cui, M. R. Oswald, M. Pollefeys Paper: arXiv:2112.12130 (CVPR 2022) Github: cvg/nice-slam
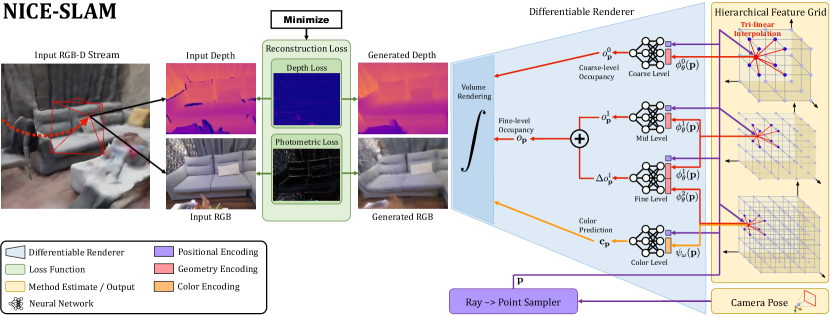
NICE-SLAM (ETH Zürich, Pollefeys 组, 2022):iMAP 的直接升级。用分层特征网格 (hierarchical feature grid) + 预训练 MLP 解码器替代 iMAP 的单一全局 MLP,系统性解决两大问题:①大场景灾难性遗忘(局部更新:只更新视锥内格点,不影响其他区域);②过平滑(多分辨率格点存局部高频特征)。同时保留 iMAP 的补全能力(coarse 层的几何先验可预测未观测区域)。
场景用 4 个特征网格表示:3 层几何网格(coarse 2 m / mid 32 cm / fine 16 cm)各配一个冻结的预训练 MLP 解码器(从 ConvONet 迁移,在合成室内数据上预训练),以及 1 个联合优化的颜色网格。Fine 层输出 mid 层基础上的残差占用,保留高频细节。
Replica 8 场景平均:completion ratio 89.33% vs. iMAP* 66.60%,精度 2.85 cm vs. iMAP* 6.95 cm。ScanNet 6 场景 ATE 平均 9.63 cm vs. iMAP* 36.67 cm。计算效率比 iMAP 跟踪快 2.1×、建图快 3.4×。
2. Key Contributions
- 分层特征网格:3 层几何 + 1 层颜色,多分辨率局部特征;仅更新视锥内格点 → 不遗忘、可扩展
- 预训练冻结解码器:几何解码器在合成数据 (ConvONet) 上预训练后冻结,提供几何先验,保留补全能力
- Fine 层残差结构:fine 层输出占用偏移 ,在 mid 基础上加细节;两级特征拼接 (见 §3.2)
- 方差加权跟踪损失:几何损失按深度方差归一化,抑制遮挡边缘不确定区域干扰
- 计算效率:格点特征稀疏表示 + 局部更新,FLOPs 仅 iMAP 的 23% (104k vs. 444k)
3. Method
3.1 分层特征网格
4 个特征网格,32 维特征,三线性插值取特征:
| 层 | 体素分辨率 | 解码器 | 作用 |
|---|---|---|---|
| Coarse () | 2 m | ,冻结预训练 | 高层结构,预测未观测区域 |
| Mid () | 32 cm (TUM: 16 cm) | ,冻结预训练 | 主要几何重建 |
| Fine () | 16 cm (TUM: 8 cm) | ,冻结预训练 | 残差细节 (依赖 mid 特征) |
| Color | 16 cm | ,联合优化 | 颜色外观 |
几何解码器 () 均为 5 层 FC 网络(隐层 32 维),在 Synthetic Indoor Scene Dataset 上以 ConvONet 方式预训练后冻结;颜色解码器 联合优化。位置编码:除 coarse 外,mid/fine 解码器对输入点 施加可学习 Gaussian 位置编码(coarse 解码器不用 PE,只吃插值特征 + 点坐标)。
视锥特征选择:建图时只更新完全在当前视锥内的格点特征 → 视锥外区域不被改写 → 无遗忘。
3.2 占用解码
任意 3D 点 的占用 = 格点特征三线性插值 + 冻结解码器:
颜色同理由单独的颜色格点 + 解码器 给出( 为颜色特征插值):
为第 层格点特征在 处的三线性插值, 为冻结解码器。Fine 解码器输入为位置 + mid/fine 两层特征(),输出占用残差而非绝对值,在 mid 基础上加细节。
3.3 体渲染
沿光线采样 点:均匀分层采样 32 点 + 深度观测附近均匀采样 16 点(观测深度 0.05D,非经典 NeRF 的 PDF 重要性重采样)。
Coarse/Fine 分别体渲染:
/ 分别为 coarse / fine 层的射线终止权重。
渲染深度和颜色:
深度方差(用于跟踪损失加权):
3.4 建图优化
三阶段交错优化(coarse 在独立进程单独跑,不参与以下三阶段):
- 仅优化 mid 层特征 → fine 级几何损失
- 联合优化 mid + fine → 同一损失
- 颜色阶段:颜色网格 + + mid/fine 几何网格;关键帧 >4 时同步 Bundle Adjustment
几何损失 (L1):
光度损失 (L1):
第 3 阶段完整目标:,。每次建图 60 次迭代,Replica/Co-Fusion 用 关键帧 1000 像素,TUM RGB-D/ScanNet/大场景用 关键帧 5000 像素。
动态异常点过滤:剔除损失超过当前帧中位数 10 倍的像素(动态物体/传感器噪声)。
3.5 跟踪
固定网格参数,只优化当前帧位姿 ;损失按深度方差加权,抑制遮挡边缘不确定区域:
跟踪目标:,。初始位姿用匀速运动模型预测(前两帧增量)。
4. Experiments & Results
数据集
| 数据集 | 场景 | 评估 |
|---|---|---|
| Replica | 8 (室内合成) | 重建质量 + 跟踪 |
| TUM RGB-D | fr1/desk, fr2/xyz, fr3/office | 跟踪 ATE |
| ScanNet | 6 真实室内场景 | 跟踪 ATE,大场景扩展性 |
| Co-Fusion | 动态物体序列 | 鲁棒性 |
| Self-captured | 多房间公寓 | 定性扩展性 |
Replica 重建质量 (8 场景平均)
| Method | Acc (cm) ↓ | Comp (cm) ↓ | Comp Ratio (%) ↑ | Mem (MB) |
|---|---|---|---|---|
| TSDF-Fusion | 1.60 | 3.49 | 86.08 | 67.10 |
| iMAP* | 6.95 | 5.33 | 66.60 | 1.04 |
| DI-Fusion | 19.40 | 10.19 | 72.96 | 3.78 |
| NICE-SLAM | 2.85 | 3.00 | 89.33 | 12.02 |
NICE-SLAM 重建质量接近 TSDF-Fusion,比 iMAP* 精度提升 4.1×,补全率提升 22.7 个百分点。
ScanNet 跟踪精度 (ATE RMSE, cm)
| Scene | iMAP* | DI-Fusion | NICE-SLAM |
|---|---|---|---|
| 0000 | 55.95 | 62.99 | 8.64 |
| 0059 | 32.06 | 128.00 | 12.25 |
| 0106 | 17.50 | 18.50 | 8.09 |
| 0169 | 70.51 | 75.80 | 10.28 |
| 0181 | 32.10 | 87.88 | 12.93 |
| 0207 | 11.91 | 100.19 | 5.59 |
| avg | 36.67 | 78.89 | 9.63 |
大场景上 NICE-SLAM 比 iMAP* 精度提升 3.8×。
TUM RGB-D 跟踪精度 (ATE RMSE, cm)
| Sequence | iMAP | iMAP* | DI-Fusion | Kintinuous | NICE-SLAM | BAD-SLAM | ORB-SLAM2 |
|---|---|---|---|---|---|---|---|
| fr1/desk | 4.9 | 7.2 | 4.4 | 3.7 | 2.7 | 1.7 | 1.6 |
| fr2/xyz | 2.0 | 2.1 | 2.3 | 2.9 | 1.8 | 1.1 | 0.4 |
| fr3/office | 5.8 | 9.0 | 15.6 | 3.0 | 3.0 | 1.7 | 1.0 |
NICE-SLAM 大幅优于 iMAP*,但仍落后传统方法(BAD-SLAM、ORB-SLAM2)。


5. Ablation & Discussion
ScanNet 6 场景消融 (ATE RMSE, cm):
| 配置 | mean | std |
|---|---|---|
| w/o Local BA | 37.74 | 30.97 |
| w/o 光度损失 | 32.02 | 21.98 |
| w/ iMAP 关键帧策略 | 12.10 | 3.38 |
| Full NICE-SLAM | 9.63 | 0.62 |
- Local BA 贡献最大 (37.74 → 9.63),去掉后退化严重
- 光度损失是第二重要项;NICE-SLAM 的关键帧策略也优于 iMAP 的策略
- std 从 30.97 降至 0.62 → 方差大幅降低,鲁棒性显著
网格层数消融 (Replica room-0): 2/3/4 层 FLOPs 分别 58k/104k/156k,3 层质量略优于 2 层,4 层因参数冗余反而略差。3 层 (coarse+mid+fine) 为最优。
计算效率 vs. iMAP:
| iMAP | NICE-SLAM | 提速 | |
|---|---|---|---|
| FLOPs (×10³) | 443.91 | 104.16 | 4.3× |
| 跟踪时间 (ms) | 101 | 47 | 2.1× |
| 建图时间 (ms) | 448 | 130 | 3.4× |
6. Strengths / Limitations / Future Work
Strengths
- 局部特征网格根治 iMAP 的灾难性遗忘;多分辨率表示保留高频细节
- 预训练几何先验让 coarse 层能补全未观测区,兼顾精度与补全
- 可扩展到多房间大场景;计算效率比 iMAP 提升 2-3×
Limitations
- 预测/补全能力仅限 coarse 层分辨率 (2 m),细节无法从先验中外推
- 无回环闭合,长距离轨迹仍有漂移
- 颜色一致性依赖局部优化,全局一致性有缺陷(需后处理)
- 内存 12 MB(比 iMAP 1 MB 高,但仍比 TSDF 67 MB 低)
Future Work
- 回环闭合集成
- RGB-only 版本(见 NICER-SLAM)
- 更细粒度的局部特征更新策略
7. Code Walkthrough
代码库: github.com/cvg/nice-slam,PyTorch 实现。
入口与整体结构
nice-slam/
├── run.py # 入口
├── src/
│ ├── NICE_SLAM.py # 主调度器,分配共享资源 + 启动线程
│ ├── Mapper.py # 建图线程
│ ├── Tracker.py # 跟踪线程
│ ├── common.py # 体渲染、射线操作工具函数
│ ├── config.py # YAML 配置加载
│ └── conv_onet/models/decoder.py # NICE/iMAP 解码器定义
└── configs/
├── nice_slam.yaml # 默认超参
└── [Dataset]/[scene].yaml
运行命令:python run.py configs/Replica/room0.yaml
NICE_SLAM.run() 启动 3 个并行进程:tracking()、mapping()、coarse_mapping()(coarse 层单独进程),PyTorch multiprocessing + 文件系统共享策略,进程间用同步屏障协调。
关键模块
Mapper.py:建图线程
核心方法 optimize_map():
- 按配置分三阶段调用 Adam 优化,参数分组(coarse/mid/fine/color 各有独立学习率)
keyframe_selection_overlap():把当前关键帧的点云投影到历史帧中,选可见度最高的 个 → 与 iMAP 随机选帧不同
关键超参(configs/nice_slam.yaml):
| 参数 | Replica | ScanNet | TUM |
|---|---|---|---|
| 建图迭代 | 60 | 60 | 60 |
| 关键帧数 | 5 | 10 | 10 |
| 建图像素 | 1000 | 5000 | 5000 |
| mid 层学习率 | 0.1 | 0.1 | 0.1 |
| fine 层学习率 | 0.005 | 0.005 | 0.005 |
Tracker.py:跟踪线程
核心方法 optimize_cam_in_batch():固定所有网格权重,Adam 只更新当前帧位姿(李代数参数化的旋转 + 平移)。损失即 §3.5 的方差加权几何 + 光度损失;匀速运动模型初始化位姿。
decoder.py:NICE 解码器
NICE 类组合四个解码器(coarse_decoder / middle_decoder / fine_decoder / color_decoder),均为 MLP_no_xyz(5 层 FC,隐层 32 维,skip connection at layer index 2,Gaussian positional embedding)。iMAP 变体只用单个 MLP(256 维,4 层,无 skip)。
common.py:体渲染核心
raw2outputs_nerf_color():实现 §3.3 的体渲染;get_samples() + select_uv() 执行均匀分层采样和深度附近采样;normalize_3d_coordinate() 把 3D 坐标归一化到 供格点插值。
论文 vs. 代码差异
| 项目 | 论文描述 | 代码实现 |
|---|---|---|
| 算法变体 | 仅描述 NICE | --nice / --imap 可切换两种模式 |
| Coarse 进程 | 与建图同步运行 | 独立第三进程,条件性开启 |
| 预训练 decoder | "冻结" | 代码中可选 pretrained/ 初始化,不强制 |
| 同步策略 | 未详述 | strict/loose/free 三档同步可配置 |
References
- Zhu, Z., et al. (2022). NICE-SLAM: Neural Implicit Scalable Encoding for SLAM. CVPR. arXiv:2112.12130
- 项目页: pengsongyou.github.io/nice_slam
- 代码: github.com/cvg/nice-slam
- iMAP 笔记:前作,本文直接改进目标
- NICER-SLAM 笔记:RGB-only 升级版
- Peng et al. (2020). ConvONet — 预训练几何解码器来源
- Mildenhall et al. (2020). NeRF (ECCV):体渲染基础,见 NeRF 笔记